How To Convert PDF To Text On Linux (GUI And Command Line)

This article presents 2 tools for converting PDF documents to editable text on Linux, using a graphical tool (Calibre) and a command line tool (pdftotext).
It worth noting that both tools used to extract text from PDF files mentioned in this article cannot extract the text if the PDF is made of images (for example scanned book pages / pictures).
Convert PDF to text using Calibre (GUI)
Calibre is a free and open source e-book software suite. It supports organizing, displaying, editing, and converting e-books, supporting a wide range of formats. The application runs on Linux, macOS, and Microsoft Windows.
Calibre should be available in your Linux distribution's repositories, and you should be able to install it using whatever software store you have on your system. For example, to install it on Debian, Ubuntu, Linux Mint, Fedora, openSUSE, or Arch Linux, use:
- Debian, Ubuntu or Linux Mint:
sudo apt install calibre- Fedora:
sudo dnf install calibre- openSUSE:
sudo zypper install calibre- Arch Linux:
sudo pacman -S calibreCalibre may also be installed on Linux by using the Flathub package (requires setting up Flathub / Flatpak on some Linux distributions).
There's yet another way to install Calibre on Linux explained on the application's downloads page, where you'll also find macOS and Windows binaries.
Related: How To Convert PDF To Image (PNG, JPEG) Using GIMP Or pdftoppm Command Line Tool
Now that Calibre is installed on your system, launch it and click
Add books to add the PDF (or multiple PDFs - Calibre supports batch converting multiple PDF files to text) you want to convert to text. From the list of books, select the PDF (or multiple PDFs for batch conversion to .txt) you want to convert to text, and click the
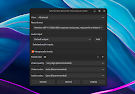
Convert books button. In the upper right-hand side of the conversion window, choose TXT as the Output format:
There are many options you can tweak in this conversion dialog. For example, you can choose to automatically remove spacing between paragraphs, or insert a blank line between paragraphs (
Look & Feel -> Layout). You can also set the character encoding and line ending style (system, unix, windows, old_mac), and even format it to markdown.After you're done with the configuration, click the
OK button to start converting the PDF to text. The converted .txt file can be found in the directory where you've set the Calibre library location (and then in AuthorName/BookName subfolders; if the author or book name can't be determined, the subfolder is called "Unknown").What Calibre lacks in this case is a way to only convert a page or a page range - it can currently only convert entire PDF files to text.
PDF-related: How To Create Fillable PDF Forms With LibreOffice Writer
Convert PDF to text with pdftotext (command line)
pdftotext is a command line utility that converts PDF files to plain text. It has many options, including the ability to specify the page range to convert, maintain the original physical layout of the text as best as possible, set line endings (unix, dos or mac), and even work with password-protected PDF files.
pdftotextis part of the poppler / poppler-utils / poppler-tools package (depending on the Linux distribution you're using). Install this package as follows:
- Debian, Ubuntu, Linux Mint, and other Debian/Ubuntu-based Linux distributions:
sudo apt install poppler-utils- Fedora:
sudo dnf install poppler-utils- openSUSE:
sudo zypper install poppler-tools- Arch Linux:
sudo pacman -S popplerIn other Linux distributions use your package manager to install the poppler / poppler-utils package.
Now that the package is installed, you can convert a PDF file to plain text and preserve its layout (I recommend using this
-layout option for maintaining the original physical layout, but you can try it without it too) with:pdftotext -layout input.pdf output.txtYou'll need to replace
input.pdf with the name of the PDF file, and output.txt with the name you want the generated TXT file to be called. Also add the paths before filenames if needed (e.g. ~/Documents/mypdf.pdf). If no output text file is specified, pdftotext will name the file with the same file name as the original PDF file.The layout option preserves the PDF layout when converting it to text, even if multi-column PDF cases.
What if you want to only convert a page range of the PDF to text, instead of the whole PDF file? Use
-f (first page to convert) and -l (last page to convert) followed by the page number, like this:pdftotext -layout -f M -l N input.pdfReplace
M and N with the first and last page number to extract, and input.pdf with the PDF filename.Want to use mac, dos or unix end-of-line characters? You can specify that too, using
-eol followed by mac, dos or unix. E.g. for unix line endings:pdftotext -layout -eol unix input.pdfIf you don't want to insert page breaks between pages, append
-nopgbrk:pdftotext -layout nopgbrk input.pdfWant to batch convert all PDF files from a folder to text files? pdftotext doesn't support batch PDF to text conversion (and
pdftotext *.pdf doesn't work), but you can convert all the PDF files in a folder to text files by using a Bash FOR loop:for file in *.pdf; do pdftotext -layout "$file"; doneFor more options, run
man pdftotext and pdftotext --help.You might like: Download Master PDF Editor 4 For Linux (Free To Use Version)